Grégoire LAURENT

Data analyst interested in Machine Learning projects
Repository of projects I worked on either during my free time or EPFL curriculum
View My LinkedIn Profile
People Analytics, end-of-year clustering and prediction
Context
At the end of each year managers are asked to bucket team members as high/medium/low performers. Idea is to try to understand if this bucketing/clustering could be done with ML clustering technics.
Objectives
Primary: Analyze impact of key metrics on end-of-year performance
Secondary: Predict end-of-year cluster based on full year performance
Content
- EDA
- Analysis
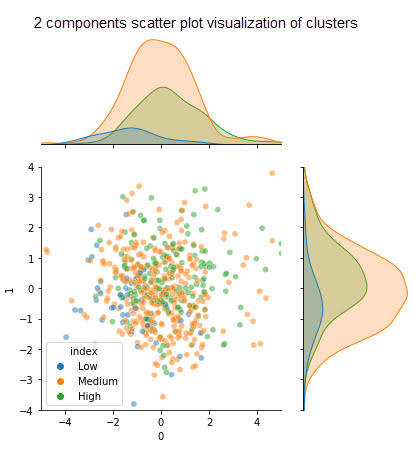
- Scatter plot
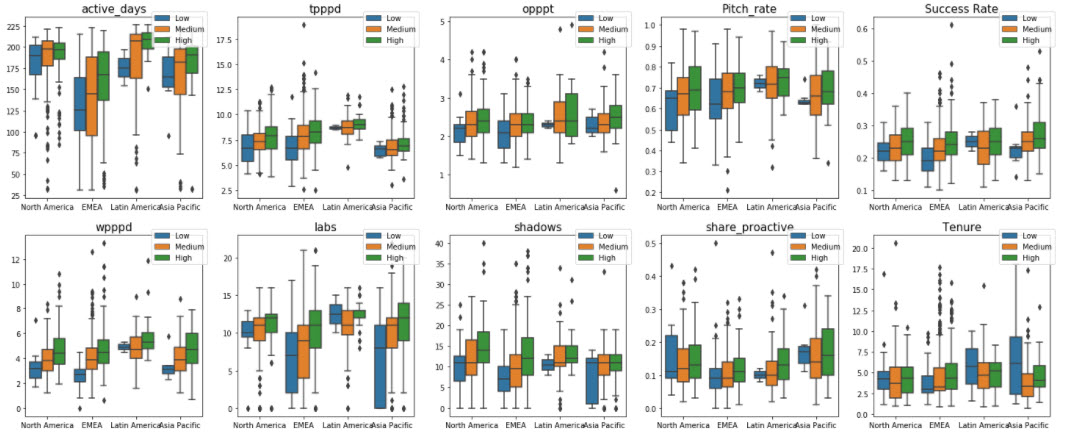
- Boxplot
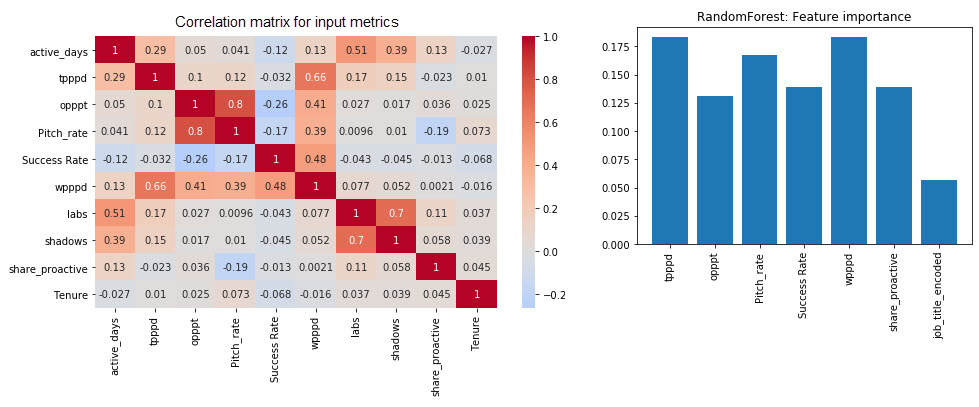
- Correlation
- ML tasks
- Encoding, Scaler, Train_test_split
- Models: Baseline, DecisionTreeClassifier, LogisticRegression, RandomForest, K-NN
- Dimensionality reduction (PCA)
Conclusion
- Can any patterns be identified for high performers – Yes, they are over-performing across selected input metrics
- Are daily business expectations aligned with end-of-year review – Yes, generally, a high performer will have out-performed on input metrics.
- Could high performers be identified solely from a this set of input metrics? – No, while a high performer will have generally out-performed on those input metrics, the inverse does NOT hold. Out-performance on input metrics did not predict high placement. We can assume that this is due to the fact that input metircs are measuring the WHAT but not the HOW (how many glasses do you break when getting the job done?) which also plays an important role.